AI人才稀缺:全面解读数据科学家成长的4个阶段
2020-12-04 来源:raincent

作者:彭鸿涛 张宗耀 聂磊 来源:大数据DT
本文带你了解数据科学家的成长之路。内容摘编自《增强型分析:AI驱动的数据分析、业务决策与案例实践》

一次偶然的机会,有一位正在深造机器学习方面学位的朋友问了笔者一个问题:如何成为一名合格的数据科学家?
这个问题回答起来亦简亦难。简单回答的话可以拿出标准答案,坐而论道地说需要编程能力、数据操作能力、数学基础、算法库应用能力、算法调优能力与业务对接的能力等。
但是这样的答案笔者其实是不满意的,因为有太多的技术意味。做数据分析、将数据的价值发挥出来,是一个“工程 + 科学”的过程,只要在这个过程中的任意一处找到自己的位置,就无谓数据科学家这种称号了。
大数据时代方兴未艾,人工智能时代又呼啸而至。人们在很多场合下能看到诸多新应用,加之整个社会都在热切地拥抱人工智能技术,使得大家都相信人工智能时代势必会改变社会的方方面面,笔者对此也深信不疑。
在人工智能时代,将数据的价值发挥出来的要素有资金、数据、平台、技术、人员等。数据科学家是人员要素中最为重要的部分,是需要企业非常重视的。在数据科学家自身发展的方向、组织结构,以及如何体现出价值等方面,相信大家肯定会有很多想法。
笔者从十几年前加入IBM SPSS进入数据分析领域开始,至今担任过分析软件工具的开发者、解决实际业务问题的数据挖掘者、数据驱动业务以及数字化转型的咨询者等多种角色。反观这些年的成长路径,将一些较为重要的经验做一个粗浅的总结,抛砖引玉,以供读者参考。

01 算法与数据科学家
我们随便打开一些教科书,会发现机器学习、人工智能、数据挖掘等经典领域所谈论的很多知识点是共通的,比如从历史数据中学习到事物模式并用于对未来做出判断,是机器学习中的重要内容,也是人工智能的重要方面,更是数据挖掘的重点内容。
现在有一个很时髦的说法,认为机器学习是比数据挖掘更为高深的学科,实现人机对话那肯定是人工智能的范畴。
其实,从一个更为宏观的视角来看的话,这几个学科都是在将数据的价值通过算法和算法的组合(数据分析的流程)发挥出来,没有一个清晰的标准说某类算法必须属于人工智能范畴、某类算法必须属于机器学习的范畴。
1. 数据科学、人工智能、机器学习等
有国外的学者试图给出一个机器学习、数据科学、人工智能等时髦名词之间关系的示意图,如图1-1所示,我们发现,这些学科间的关系可以说是交缠不清。

图1-1 数据科学相关的学科之间的关系笔者也就这些学科之间的关系进行了深入探索,查询了很多的资料,发现图1-1的中间部分,其实是来自SAS在1998年提供的数据分析的课程。除此之外,很少有人能将它们的关系说清楚,因为这本来就说不清楚。所以,对上图,读者只当其是一个参考即可。
重点是图1-1所表达的含义:这些技术都是围绕“问题解决” →“分析” →“策略” →“领域知识” →“沟通” →“表达” →“探索”等问题来展开的,而这些问题都是人们在认识世界、解决问题时所涉及的方面。
所以,本节采用图1-1想表达的含义也是如此:计算机的技术在迅猛发展,现在很多的技术都可以融合使用来解决复杂问题了;对于数据科学相关的这些技术,很多方面都是通用的。
2. 室内活动还是室外活动
数据科学家是个含义较广的名词,人们往往也不会太多在意他们所从事的具体工作有什么不同,习惯将从事算法设计开发、在客户现场直接应用数据分析工具解决问题的人都称为数据科学家。
这样的划分其实无可厚非。但是若将算法看作成品,则可以将数据科学家分为室外(out-house)和室内(in-house)两种角色。
所谓室内数据科学家关注具体算法的设计、实现。比如,在MapReduce的计算方式下如何实现分层聚类算法。
而室外数据科学家,也就是数据挖掘者,他们一般不需要关注具体算法和工具的实现,他们的职责是将客户的需求翻译为具体工具能解决的工作流程,并应用合适算法能得出有意义的结论。图1-2比较形象地对比了两种科学家的不同。

图1-2 室内室外两种数据分析人员职责对比现在还有一种习惯就是将室内数据科学家称为算法工程师,而对于室外数据科学家则称之为数据科学家。我们大可不必纠结于这些名称的不同,只要对他们的职责有不同的认识即可。
室外数据科学家,在长期的项目过程中,需要与业务人员有非常深入的沟通才能得出有意义的数据分析结果。所以,相对于数据模型而更加看重业务的需求和特点,这是室外数据科学家的基本素养。本书所谓的数据科学家是指所谓从事室外活动的数据分析者。
02 数据科学家不断成长的几个阶段
现在移动端各种App百花齐放,这已经使得信息的传播没有任何的限制,人们在不自觉的过程其实已经阅读了大量的自己感兴趣的文章。若对机器学习比较感兴趣,相信人们已经看到了很多非常炫酷的机器学习的应用,如人脸识别的精度已经提高到一个非常高的水平、大量智能问答机器人的部署已经替代了不知多少呼叫中心的员工等。
显而易见,这些应用绝不是单靠一个算法就能解决的,注定是平台、算法、业务等要素的综合应用才能产生这样的效果。在应用数据分析时已经基本形成一个共识,就是数据分析者要对业务有一定的了解,才能保证产生较好的结果。
Gartner很早就将数据分析能力分成了4种(如图1-3所示):
描述性分析(Descriptive Analysis)是在回答“过去发生了什么”,是了解现状的有力手段;
诊断分析(Diagnostic Analysis)是寻找“为什么会是这样”的方法;
预测分析(Predictive Analysis)是在回答“将来会是怎样”;
规范分析(Prescriptive Analysis)则是说“基于现状、预测等结果,我如何选择一个较优的决策得到期望的结果”。

图1-3 四种分析能力划分(Gartner)Business Intelligence的核心能力是解决描述分析和诊断分析。人们常说的预测模型(包括传统的随机森林、GBT等,还包括深度学习的常见算法如CNN等)、聚类模型、关联分析等都属于预测分析范畴。利用凸优化、马尔可夫等方法从众多的决策选项中寻求最优决策,则属于Prescriptive Analysis的范畴,重点解决最优决策的问题。
在图1-3中,分析之后,人们经验、业务的输入(Human Input)随着分析手段的提高而减少,这是因为Prescriptive Analysis在分析过程中已经将这些因素充分地引入。
比如,预测客户流失的模型能够输出“哪些客户将要流失”的名单,但是并不会输出“OK,企业应该采用何种决策来挽留”,是应该给个折扣,还是办一张会员卡?这些还是需要人们进行业务决策的输入。
而Prescriptive Analysis则会分析折扣和会员卡哪种方式既能挽留客户又能使得企业的收益较高,但是这些决策(会员卡和折扣)也是需要人们输入后才能进行分析。
所以“通过数据分析的手段发挥数据价值”的过程,没有业务输入是绝对行不通的。所以,笔者也认为数据科学家绝不是仅仅精通算法即可,还需要对业务一直保持热情,不断思考如何发挥数据分析的业务价值。我们需要从技能、效果、工作内容、工作方法等多个层面来扩展相关的能力,这才能发挥较大的价值。
总之,如果数据科学家仅仅只是被动地考虑用何种算法满足业务部门所提出的要求的话,是远远不够的。
如果读者有志于成为一个数据科学家,或者已经是一个数据科学家,类似于职场的职业路径规划,数据科学家的成长路径可以是什么?如何不断成长?相信大家按照自己的兴趣都有不同的理解。
若数据科学家一直致力于“发挥数据的价值”这条主线,那么笔者认为从价值的大小上可以分为算法、用法、业务、战略4个层面(如图1-4所示),数据科学家也可以沿着这条路径来成长。
从图1-4中可以看到不同层面的数据科学家的职责和作用是不同的,4个层次也是数据科学家成长的不同阶段。

图1-4 数据科学家成长的4个阶段1. 算法——如何构建数据分析模型
人们总是津津乐道各种时髦的算法,感叹算法的发展使得人工智能有了长足的进展。比如,人们看到机器可以精准地识别人脸、机器可以作诗、机器可以识别图片内容并“说出”符合其内容的文字描述,也热衷于紧跟最新的技术发展来做一些新颖的应用。这是一个非常好的趋势,可以促进人工智能的相关产业发展。
然而,人类已经发明的算法远不仅仅如此。若读者一直在从事数据分析的相关工作,会发现其实能够解决实际业务问题的算法非常多,有很多也是简单直接的。
比如,找到潜在的价值客户,既可以通过响应预测的模型,也可以通过聚类分析的模型,还可以通过社交网络分析的模型来找到。构建这些模型所需要的相关知识也需要体系化地学习、不断积累才能真正满足实际的业务需求。
在很多数据挖掘的资料中都会把算法分为有监督的学习、无监督的学习等类别,每个类别下各自的算法又有不同。比如聚类算法属于无监督的学习范畴,而能够做类别判断或回归的算法都属于有监督的学习范畴。
在实际使用时,需要针对需求灵活应用,如可以先用决策树算法生成预测模型,然后分析决策树的分支来细分客群。只有对这些算法有一个体系化的学习,才能达到灵活应用的目的。
超参数(Hyperparameter)是在给定数据集的情况下,确定一组参数组合能使得模型性能、泛化能力达到较优。
每个算法在调试超参数的过程中,都有一些与算法特征相关的普遍规律,如随机森林算法中决策树的个数、决策树的深度等,一般是需要预先被设定和关注的。基于随机森林中每棵树应当是一个弱分类器的原理,决策树的深度应该很小才能避免过拟合。
目前有Grid Search等工具能够在不同参数组合下尝试找出一个合适的超参数,替代人们不断进行手工尝试的过程。但是不论如何,设置算法参数时总有一些经验总结可以在后来的应用中被复用。
在深刻了解算法原理、算法体系的基础上,掌握参数调优的技能是一个数据科学家的基本能力。不论是对初学者还是有一定经验的从业者来说,这都是一个需要不断学习和积累的基本任务。
2. 用法——如何回头看模型
在很多情况下,当数据科学家花费大量时间和精力构建出模型后,兴高采烈地试图交给业务人员进行使用时,往往会遇到一个有趣的情况:业务人员听不懂你对高深算法的解释,甚至不在乎你对数据的各种费心处理,他们只关心实际的问题,如模型到底效果如何?
在很多情况下,模型构建完成后需要对模型进行验证。比如训练时采用截止到3月的数据,而模型部署是在7月,所以需要数据科学家验证截止到6月的情况下,模型的实际效果能达到什么程度。
这时,我们除了需要通过新数据计算模型性能指标(如提升度、准确性、稳定性等)外,还需要计算模型实际业务结果会是怎么样,能带来多少收益或能避免多少损失(如图1-5所示)。
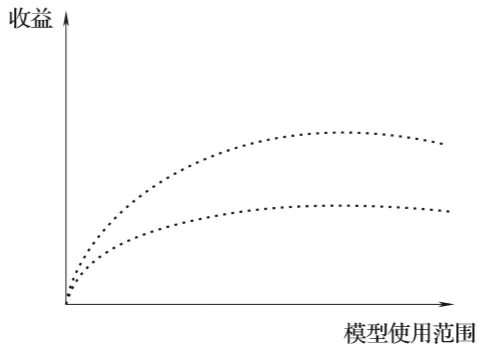
图1-5 以简单明了的方式来讨论模型使用的预期价值数据科学家除了要对模型性能指标熟稔于心外,还需要能够表达清楚模型真正的实际价值。所以,在第一步模型构建完成后,应用两套指标来衡量是比较可取的做法——模型性能指标是从数学角度说明模型优劣;业务指标是从模型应用的业务结果来评价其价值。
在现实中,人们往往不好准确把握模型的真实业务价值,在实际应用后通过数据统计才能有结论。
但是这一点都不妨碍模型部署前的估算:按照目前模型的性能指标,估计在第一次给定客户数的情况能有多少人购买,大致的营业额会是多少。采用估算还是采用事后统计,都是用以说明模型业务价值的手段,可以灵活应用。
数据科学家要像重视模型性能指标的计算一样重视模型所带来的业务指标的计算。
总体来讲,数据科学家不能将自己的工作范围只框定在纯粹建模,需要“抬头看”和“睁眼看”业务价值。
3. 业务——如何产生更大价值
业务问题的解决,可以从一处痛点开始突破,也可以按照体系化的方法整体解决。
比如,银行对理财产品的营销:
若只关注具体产品的销售,则简单的产品响应预测模型即可解决;
若只关注一批产品的销售,则也可以通过构建多输出预测模型预测每一个产品的购买概率来生成推荐列表;
若关注客户旅程地图(Customer Journey Map)而确定营销时机,则需要一批模型;
若关注客户体验的提升,需要的就不是一批模型,而是一个体系化的平台加大量模型才能达到预期效果。
大多数情况下,数据科学家应当在具体的业务背景下展开工作。比如,若业务部门按照客户旅程地图的方法来分析客户特征、了解客户需求、并适时推荐产品(如图1-6所示),则数据挖掘的模型是服务于一个个业务场景,在整体客户关系管理的框架下发挥价值。
数据科学家的工作需要深度融入业务,甚至引领数据驱动的业务发展。此时,数据科学家的定位不应该仅仅是构建模型者,还应该是数据驱动业务这种新模式的搭建者。
这种角色变化就要求数据科学家深刻理解具体的业务、新的数据驱动模式的运作方式,围绕数据驱动模式而展开各种活动的意义。

图1-6 以客户旅程地图为例说明不同的业务场景需要相应的模型在这种情况下,数据科学家在构建模型时需要明确:该模型在数据驱动业务的新模式中在哪个阶段发挥什么作用?如何构建一个模型组来协同工作?有了这些模型后数据驱动业务模式能够做到什么程度?
4. 战略——如何更广
数字化变革是目前几乎所有企业都无法回避的任务。企业由于所处行业、自身特点等原因,需要量身定制数字化转型的战略。大型企业需要选择发展重点作为突破方向,在转型过程中既要做好技术基础,也需要大力推行敏捷的方法,同时要对人们的观念、组织内的流程等方面做出更新(如图1-7所示)。
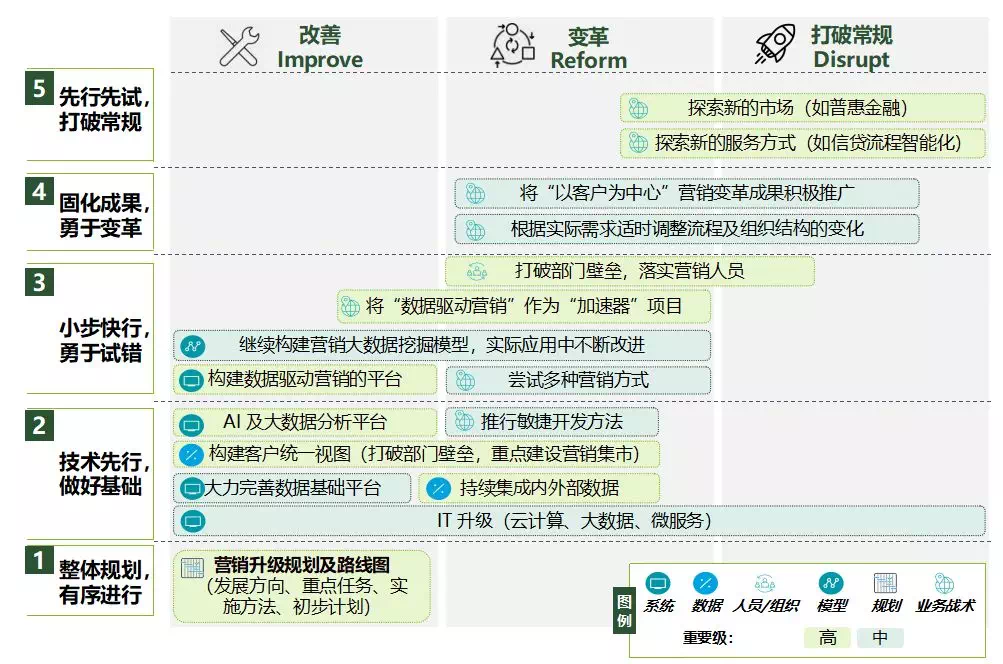
图1-7 一个量身定制的数字化转型路线图示例资深数据科学家或首席数据科学家所担负的职责不应该仅仅是完成目前安排的任务,或者去做一些博人眼球的所谓智能应用。其还应该深度参与企业数字化转型的战略制定、计划安排、引领加速器项目等工作,因为资深数据科学家最应该懂得数据的价值如何发挥、能够发挥到什么程度。
对于大型企业而言,数字化转型的任务是艰巨的,不过众多行业已经或多或少地开始了相关的行动。笔者由于工作关系也深入参与到了大型金融机构数字化转型的咨询工作,深刻感触到了企业在进行数字化转型时的困难。这使得笔者更加认为让真正懂得如何发挥数据价值的人员按照加速器的方式来推动数字化转型进程是至关重要的。
关于作者:
彭鸿涛,德勤企业咨询总监兼首席数据科学家,德勤全球AI团队核心成员,德勤数字化转型、智慧营销、智慧风控、客户体验等核心咨询服务方案的资深顾问。
张宗耀,上海全应科技有限公司资深数据科学家,前华为企业智能部门资深数据科学家,前IBM SPSS 算法组件团队资深算法工程师。
聂磊,陕西万禾数字科技有限公司CTO,前IBM SPSS 资深数据科学家,前IBM Watson Analytics数据分析引擎技术主管及架构师。
本文摘编自《增强型分析:AI驱动的数据分析、业务决策与案例实践》,经出版方授权发布。
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

上一篇:数据分析与数据科学的未来
