性能超前,详解腾讯云新一代Redis缓存数据库
2018-06-17 12:07:19来源:未知 阅读 ()

背景
当前内存数据库发展迅速,用户对于存储系统的要求也越来越高,为了满足各类业务场景的需要,腾讯云设计了新一代的内存数据库,不但保留了原来系统的高性能,高可用等特性,同时还兼容了当前流行的Redis原生协议及使用方式。我们试图在解决原生方案短板的基础上,不断创新,使得新系统同时具备易懂、易用、易维护、高可靠、低成本等特点。主要体现在以下几个方面:
1.沿用了上一代自研系统使用共享内存的数据存储方案,避免Redis采用AOF机制,恢复时间过久的问题,极大的降低了在升级、进程异常等场景产生的影响。同时,使用全新的快照与流水机制,解决了Fork机制造成的内存预留问题
2. 在存储引擎方面,对于自研及开源方案进行重新分析整理,进行了再次创新,不但使用多规格Block灵活组合的存储方式,内部数据结构同样采用动态页管理,对比原生引擎,极大的提高了内存使用率的同时,也降低了运行过程中产生内存碎片的机率
3. 单进程多线程的模型让运维部署更加简便,同时精简模块数量,让请求路径更短
4.更加精细化的数据管理,实现快速的过期淘汰及精确的LRU特性
5.实现了强一致特性,满足了金融等业务对于数据一致性的强需求
6. 集群版模式中,支持了多数据库的场景,降低用户由主从版迁移至集群版的使用门槛
7.存储节点可直接转发用户请求,降低后台数据变更对于客户端的依赖,原生主从版客户端可直接访问集群版,无需修改代码
8.我们正在兼容更多的原生数据库协议,让更多的用户可以无缝切换,体验更多的新特性
技术架构优化历程
在架构方面我们将当前比较流行的两层(不包含客户端)结构简化成了单层,如下图所示。
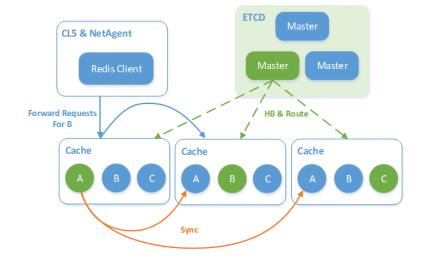
图1 架构图
图中的Master为集群的管理节点,每组Master管理一个地域的若干集群。
Cache则是实际的数据存储节点。架构中不再显式设置接入层,而是通过Cache转发用户请求,这样做的好处:
・ 单纯的存储或接入模块,由于对不同资源类型(CPU、网卡、内存等)需求的倾斜,无法很好的提高当前高配机型的设备利用率。也基于这个原因,理论上合并后的单层结构能更好的利用硬件资源,节约成本
・ 减少模块数量可以减少大量运维操作,便于运维同学部署及规划资源等
・ 路由更接近数据,因此在某台Cache上进行数据迁移动作时,可以更加实时的对用户请求做出应对(转发至最新的目标),减少变更对用户请求的影响
针对一些对于接入层有强需求的场景,比如,某业务的客户端链接数极多,我们也有针对性的做了优化。Cache可退化为纯接入机使用,这样可以方便的扩展为两层结构,统一使用一套代码,无需单独维护。
数据分布方面,采用了全部打散的方式,即在任意一台Cache上既有主数据也有(其他业务)备份数据,完全以Shard为粒度(物理内存单元)进行管理,如下图所示。
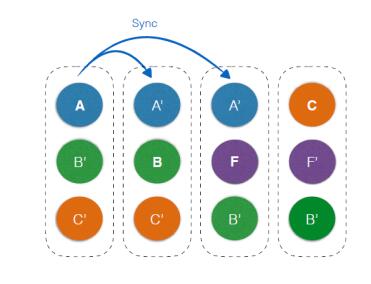
图2 Shard分布
每台Cache的内存被划分为若干Shard,无论是主从版还是集群版,用户的主或备数据可能落到任意Cache,分配策略支持跨机架、跨机房等。这样做的目的有:
・ 不再有单纯的热备设备,减少低负载设备比例,充分利用整个集群的网卡、CPU等资源
・ 当一个或若干节点异常时,利用整个集群的能力进行容错(切换流量)与恢复(在不同节点重建备份),避免雪球效应
・ 在分配时,将考虑现有设备主备Shard比例及负载,优化装箱算法,可是集群资源更加均衡
由于CKV+兼容Redis协议及各种使用场景,因此也区分了主从版与集群版。对于集群版来说,经过对比,数据哈希仍然采用了Pre-sharding的方式,如下图所示。
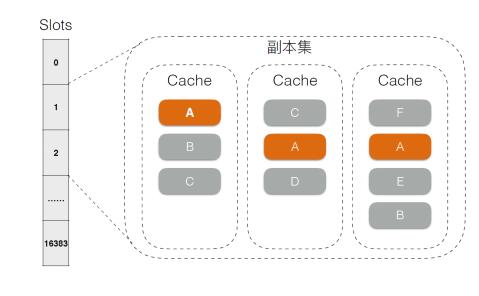
图3 数据哈希
对于单个Shard来说,最大可管理内存为8T,由于目前设备限制,实际最大可支持512G,因此集群版支持的容量范围为 [1G,512G] * 16384 = [16T,8P]。当然在实际应用中,还需考虑系统内部预留资源等因素,且Shard大小及Slot对应关系的规划也要视物理资源情况而定。
内存引擎设计,确定CKV+引擎
内存管理是内存数据库系统中非常重要的一环,在CKV+系统的设计阶段,对于引擎也是进行了大量的讨论与调研,根据我们的经验,同时吸纳了多种主流内存管理体系的优点,确定了当前CKV+的引擎方案。主要特点归纳如下:
・ 使用共享内存,方便升级或进程异常时快速恢复
・ 基于共享内存实现了红黑树算法,在保证性能的前提下,兼容Redis中的Hash、Set、ZSet数据类型
・ 使用多规格Block作为(最小的)数据存储单位,更加灵活同时内存空隙更小
・ 使用经典的Page管理模式,优化了动态分配策略,提高了Page回收几率,降低内存碎片率
・ 用户数据所依附的内部数据结构同样基于Page进行动态分配,减少内部预留空间的浪费
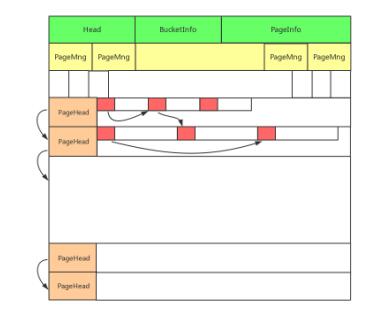
图4 内存引擎
内存引擎的一个重要指标就是内存使用率,我们与原生Redis存储进行了对比测试。
测试方法:使用同样的随机数据,分别写入Redis及CKV+的1G实例,对比实际存储数据量的多少。
样本大小:key [10,30],Value [20,100]
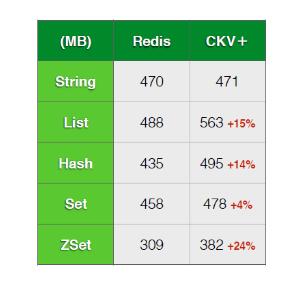
图5 使用率对比
测试结果显示,在简单String类型的场景下,两者存储量近似,但在稍复杂的结构中,CKV+则可以存储更多的用户数据。
大胆尝试,采用单进程多线程模型
对于内存数据库来说,高性能仍然是大前提,而开发过程中使用的线程模型及框架对于这个层面影响较大。因此在设计初始,我们对于这部分也做了大胆尝试。
首先,我们使用了单进程多线程的模式,而非大多开源系统的单进程单线程的路数,一方面可以更好的利用整机资源,另一方面也能降低运维门槛。对于多线程来说,需要解决的主要问题有如下几点:
・ 若干线程共同管理内存则势必需要引入锁,而高配机型核数多、线程多,加锁可能带来毛刺
・ 单个进程需要管理多个业务数据,特别是主从版,每块内存Shard容量较大,难免有比较庞大的kv数据,同时主从版支持部分耗时操作,需要尽量减少实例间的相互影响
・ 线程间通信或共享数据的代价要小,比如同步路由信息等
・ 同时要考虑诸如线程上下文切换、CPU缓存命中率、IO等因素
在进行了一系列的调研工作后,最终确定线程模型为:每个物理核启动一个线程,管理若干内存Shard,如下图所示。
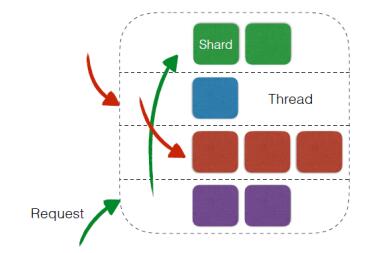
图6 线程模型
使用这种模式的主要考虑:
・ 具体内存的操作仅由某一个CPU处理,避免加锁,某个Shard出现热点时,对其他线程管理的实例影响较小
・ 在管理实例数量不多的情况下,空闲CPU可以处理网络及磁盘IO,以及请求的编解码等工作,提高整机资源利用率
・ 线程间不存在依赖或竞争关系,避免不必要的损耗
性能测试
性能应该是大家比较关注的部分,我们针对Redis的String与ZSet两种数据结构进行了性能测试,结果如下。
注:
・ "单实例"表示一台Cache仅管理 1 个Shard,"N实例"则表示同时管理N个Shard
・ 所有测试均使用 2400 个客户端对整台设备进行压测
・ 测试不涉及消息转发,即客户端直接请求数据所在设备
・ 测试样本分别使用10Byte与100Byte的数据
・ 本次测试并未启用DPDK,后续会进行补充
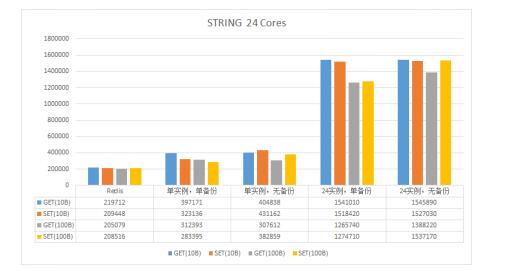
图7 STRING类型读写性能对比

图8 ZSET类型读写性能对比
结语
腾讯云新一代内存数据库不但全面兼容了Redis的数据结构及使用方法,同时解决了原生方案在备份、容灾等方面的不足。在性能方面,我们并没有满足于现状,后续还将更细致的优化逻辑流程,并引入DPDK等特性,进一步提升系统性能。成本也是我们关注的重点,当前的系统架构与线程模型能更好的适应不断提升的硬件设备性能,提高硬件资源的利用率,同时,我们也将引进冷热数据分离等技术,在保证性能的前提下,更好的为用户节省成本。
作者 :carloszhao, 2010 年加入腾讯,前后参与过分布式计算、存储等多个项目的设计与开发,目前在腾讯TEG-基础架构部,负责内存数据库的研发工作。
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

下一篇:没有了
- 2017云栖归来 天旦以实力证明全新的DB性能监控优势 2018-06-17
- 129元高性能“海豚云主机”引爆市场 性能评测 2018-06-17
- 优化网站性能 谷歌提供主机网站服务工具 2009-05-12
- 外国人评比的五大最佳性能的FTP客户端工具 2009-05-12
- [转帖]alexa 网站的五星级详解 2008-02-22
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
