数据公民:为什么我们这么关心数据道德
2018-07-16 来源:raincent

• 数据公民受到由数据科学家创建的模型、方法和算法的影响,但他们能够对这些工具施加影响的方式却非常有限。
• 数据科学伦理可以利用现有领域的概念框架来指导如何处理道德问题,比如公民学。
• 数据科学家也是数据公民。他们也会受到数据科学工具的影响,但同时也在构建这些工具。通常情况下,这些角色发生冲突的地方,正是人们了解发展道德体系重要性的突破口。
• 确保数据公民权利的一种模式可能是为数据科学寻求与律师和立法者同等水平的道德实践透明度。
• 与之前的其他道德运动一样,寻求更好的环境保护或更公平的工作条件、大规模实现新的权利和责任需要进行大量的游说和宣传。
我不是数据科学家,但我仍然关心数据科学道德。我关心它的原因与我关心公民学的原因相同:我不是律师或立法者,但法律正影响着我的生活,让我想知道该如何有效地成为一个公民。数据公民正受到由数据科学家创建的模型、方法和算法的影响,但他们能够对这些工具施加影响的方式却非常有限。数据公民必须向数据科学家提出严正声明,以确保他们的数据得到合乎道德的利用。数据科学伦理学是一个新领域,我们似乎需要重新发明所有的工具和方法,以便从头开始开发这个领域。事实是,我们可以利用现有领域的概念框架——比如公民学——来创建构建数据伦理所需的一些新工具、方法、流程和程序。
“法律”和“数据科学”都是具有不确定边界和层次结构的概念。我已经意识到了这一点,但在本文中,我会假设它们属于同一概念,而不是由不同部分拼凑在一起的东西。
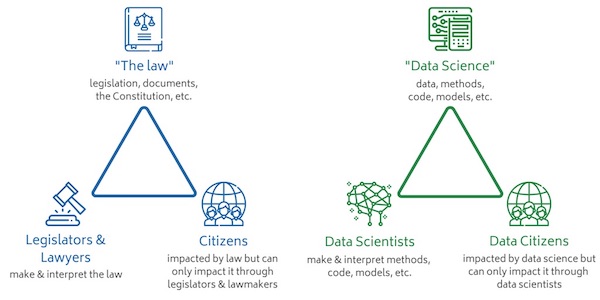
在公民生活中,公民有影响立法者和律师决策的权利。尽管这些系统并不完美,反映了不平等的社会权力结构,但公民的这些权利确实是存在的。在公民生活中,我们可以为我们认为最能代表我们的政党和个人(他们代表了我们对如何制定和实施法律的看法)投票。我们可以请愿和游说,表达我们的意见。如果这些都不奏效了,我们可以进行抗议游行,还可以通过调查和诉讼来寻求补救。
然而,在数据公民的世界中,这些权利没有明确的定义。即使想要发现偏见也可能极具挑战性,因为很多数据科学成果都是专有知识。对于那些没有资源进行大规模研究的人来说,这些情况可能没有那么明显,比如招聘算法会在无意中导致恶性贫乏循环,或者犯罪风险评估软件在评估风险方面表现很差,但在区分人类种族方面却很擅长,或者翻译软件会在翻译中暗示性别倾向,但原文可能并不包含任何性别倾向。
当然,这些都是被公开发现和研究过的例子,还有很多其他例子没有引起注意或没有受到质疑。在“Weapons of Math Destruction”一书中,作者Cathy O’Neil描述了一个年轻人,他因为无法通过性格测试而一直被雇主拒绝。O’Neil指出,这些测试认为候选人不合适,但它们从未得到关于被拒绝候选人是否可以胜任其他岗位的反馈,也就是说,并没有确凿的证据表明这类测试是否有效。所幸的是,这位年轻人的父亲是一名律师,他对在招聘中使用这类性格测试提出了质疑。通过这样一个不公平的案例,这位律师就能够为所有人争取更平等的待遇。要认识到这种反复出现的障碍(未能通过性格测试)可能是歧视的证据,需要具备专业的知识,但这不是每个人都具备的。
O’Neil在她的书出版后不久参加了InfoQ的播客节目,她明确指出,量刑算法“等同于一种法律”,它们可被视为一种“数字算法法律”。与法律的其他部分不同,因为人们根本无法了解这些算法的工作原理。即使人们明确知道这些“法律细则”,但他们却不知道该如何追索这些算法对他们进行的“审判”或对他们做出的预测。O’Neil认为,作为数据公民,我们都应该得到“……与法律相同的保护,基本上这是符合宪法精神的。我们应该有权利知道规则是什么,对于这些强大的算法来说也是一样的“。对于在判决、招聘及其他方面应用由偏见的算法,O’Neil指出,”机器学习算法不会问’为什么’……它只会寻找模式并重复它们……如果我们有一个不完美的系统,并且把它自动化,我们就会重复过去的错误“。数字系统并不会让一切更加公平,但数据公民(通常是数据科学家)通常认为系统化的结果会更客观。但事实不是这样的,O’Neil说。
这个三角模型中的角色存在重叠:立法者也是公民,数据科学家也可能被糟糕的算法错误分类。通常情况下,在这些角色发生冲突的地方,正是人们对发展数据科学道德实以及发展数据科学道德所需手段做出充分理解的突破口。在播客中,O’Neil指出,“数据科学家在工作期间必须做出道德决定,即使他们不承认这一点(他们通常不会承认)”。帮助数据科学家认识到他们的责任对于协商数据公民与数据科学之间的关系来说至关重要,或许我们可以以数据科学家本身也会受到自动化决策影响为例,因为他们其实也是数据公民。
那么,作为数据公民,我们如何让影响我们的“数据科学”更有效更公平呢?第一步可能是要为数据科学争取与律师和立法者同等水平的透明度。GDPR在某种程度上将数据公民的权利编入法典,并惩罚违反这些权利的组织。而对于数据科学,有四个关键的条款。它们是:
首先,数据访问权利,数据主体有权了解如何以及基于什么样的目的处理他们的个人数据,并有权获得数据的副本。
第二,被遗忘的权利,个人可以要求删除他们的数据,不再与第三方共享。
第三,数据可移植性,个人可能会要求将其数据传输到另一个处理器上。
最后,隐私设计不再只是一个行业上的设计概念,而是法律提出的要求。
这些权利将影响数据科学家设计模型的方式。数据可能发生变更,因为人们会要求删除其数据或者使用最少量的数据来构建模型,所以在开发数据科学工具时需要考虑这些新的因素。
除了GDPR之外,数据科学界也对编撰道德法则进行过很多尝试。开放数据研究所的数据伦理画布就是一个例子,Gov.uk的数据科学伦理框架是另一个例子,公共科学图书馆的“可靠大数据研究的十个简单规则”是第三个例子。Cathy O’Neil的ORCAA咨询服务现在也提供算法审计,微软和Facebook等大型技术公司也正致力于开发审计工具包。埃森哲是最早推出公平原型工具的公司之一,该工具旨在识别和修复存在于算法中的偏见。然而,要让工具真正发挥作用,“你的公司还需要有一种道德文化”,埃森哲道德AI主管Rumman Chowdhury说。否则公司会很容易就忽视该工具提出的建议,并继续施行有偏见的做法。
大多数数据公民都不是数据科学家,当数据科学家决定使用特定代码库或调整某个变量的权重时,我们也并非能够对此作出道德审判的人。在开发模型时,我们不会选择要包含哪些信息以及要忽略哪些信息。但我们能做的就是让自己熟悉错误的例子,并找出原因,以及那些进展顺利的例子。我们可以基于这些例子批判性地审视我们与数据的交互方式,特别是当数据被用于制定有关我们的决策时。但是有些人扮演着两种角色:数据科学家知道由其他人在他们的领域所做出的道德决策将如何影响他们自己、他们的家人、他们的朋友,以及使用他们服务的数据公民。作为这些系统的创建者,数据科学家有责任和手段用好这些数据。
与之前的其他道德运动一样,寻求更好的环境保护或更公平的工作条件、大规模实现新的权利和责任需要进行大量的游说和宣传。所幸的是,像doteveryone和Coed:Ethics这样的团体正在努力向政府和公司施加压力,以便创建一个拥有更公平算法的世界。
Caitlin McDonald将在7月份于伦敦举行的Coed:Ethics大会上讨论算法对公民的影响,这是第一次从开发人员的角度讨论技术伦理的会议。
关于作者
Caitlin E McDonald博士是一位屡获殊荣的学者,也是一位数字社区和数据科学方面的作家。她拥有定性和定量研究方法的经验,专注于人类想象力与数字系统的交叉研究。Caitlin于2011年获得了埃克塞特大学博士学位,专注于研究文化和艺术社区如何适应日益全球化的世界。
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

下一篇:数据中心的可见性价值
