机器学习【算法】:KNN近邻
2018-09-19 02:52:07来源:博客园 阅读 ()

引言
本文讨论的kNN算法是监督学习中分类方法的一种。所谓监督学习与非监督学习,是指训练数据是否有标注类别,若有则为监督学习,若否则为非监督学习。监督学习是根据输入数据(训练数据)学习一个模型,能对后来的输入做预测。在监督学习中,输入变量与输出变量可以是连续的,也可以是离散的。若输入变量与输出变量均为连续变量,则称为回归;输出变量为有限个离散变量,则称为分类;输入变量与输出变量均为变量序列,则称为标注
有监督的分类学习
KNN算法的基本要素大致有三个:
1、K 值的选择 (即输入新实例要取多少个训练实例点作为近邻)
2、距离的度量 (欧氏距离,曼哈顿距离等)
3、分类决策规则 (常用的方式是取k个近邻训练实例中类别出现次数最多者作为输入新实例的类别)
使用方式:
K 值会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,是预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最有的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。
距离度量一般采用 Lp 距离,当p=2时,即为欧氏距离,在度量之前,应该将每个属性的值规范化,这样有助于防止具有较大初始值域的属性比具有较小初始值域的属性的权重过大(规范)
算法中的分类决策规则往往是多数表决,即由输入实例的 K 个最临近的训练实例中的多数类决定输入实例的类别
简述
KNN分类算法,是理论上比较成熟的方法,也是最简单的机器学习算法之一。
该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
一个对于KNN算法解释最清楚的图如下所示:
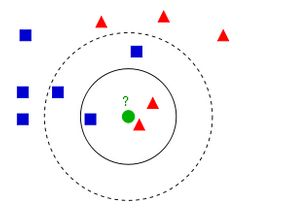
蓝方块和红三角均是已有分类数据,当前的任务是将绿色圆块进行分类判断,判断是属于蓝方块或者红三角。
当然这里的分类还跟K值是有关的:
如果K=3(实线圈),红三角占比2/3,则判断为红三角;
如果K=5(虚线圈),蓝方块占比3/5,则判断为蓝方块。
由此可以看出knn算法实际上根本就不用进行训练,而是直接进行计算的,训练时间为0,计算时间为训练集规模n。
knn算法在分类时主要的不足是,当样本不平衡时,如果一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。
*算法实现
1、函数
输入: 训练数据集 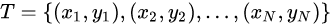 ,其中
,其中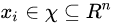 为训练实例的特征向量(
为训练实例的特征向量(
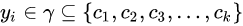 为训练实例的类别(
为训练实例的类别(
输出: 新输入实例
1、根据给定的距离度量,在训练集T中找到与
2、在

其中I为指示函数,仅当
2、距离度量方式
较为常用的距离度量方式是欧式距离,定义可以使用其他更为一般的
设特征空间









3、K值选择
一般会先选择较小的k值,然后进行交叉验证选取最优的k值。k值较小时,整体模型会变得复杂,且对近邻的训练实例点较为敏感,容易出现过拟合。k值较大时,模型则会趋于简单,此时较远的训练实例点也会起到预测作用,容易出现欠拟合,特殊的,当k取N时,此时无论输入实例是什么,都会将其预测为属于训练实例中最多的类别。
4、分类决策规则
常采用多数表决规则。对于给定的实例

要使误分类率最小即经验风险最小,此时要使得

https://github.com/undersunshine/machine_learning_algorithms/blob/master/K_nearest_neighbor/KNN.py
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- Python学习日记(十) 生成器和迭代器 2019-08-13
- python学习-53 正则表达式 2019-08-13
- python爬虫学习之爬取超清唯美壁纸 2019-08-13
- python爬虫学习之用Python抢火车票的简单小程序 2019-08-13
- Python学习日记(九) 装饰器函数 2019-08-13
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
