Python终究教程!语音识别!大四学生实现语音识…
2018-07-19 05:47:24来源:博客园 阅读 ()


▌语言识别工作原理概述
语音识别源于 20 世纪 50 年代早期在贝尔实验室所做的研究。早期语音识别系统仅能识别单个讲话者以及只有约十几个单词的词汇量。现代语音识别系统已经取得了很大进步,可以识别多个讲话者,并且拥有识别多种语言的庞大词汇表。

▌选择 Python 语音识别包
PyPI中有一些现成的语音识别软件包。其中包括:
?apiai
?google-cloud-speech
?pocketsphinx
?SpeechRcognition
?watson-developer-cloud
?wit

$ pip install SpeechRecognition
安装完成后请打开解释器窗口并输入以下内容来验证安装:

以上七个中只有 recognition_sphinx()可与CMU Sphinx 引擎脱机工作, 其他六个都需要连接互联网。
SpeechRecognition 附带 Google Web Speech API 的默认 API 密钥,可直接使用它。其他六个 API 都需要使用 API 密钥或用户名/密码组合进行身份验证,因此本文使用了 Web Speech API。
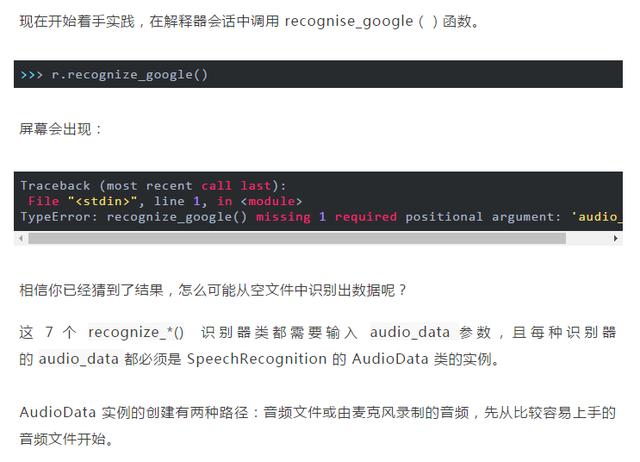
▌音频文件的使用
首先需要下载音频文件(https://github.com/realpython/python-speech-recognition/tree/master/audio_files),保存到 Python 解释器会话所在的目录中。
AudioFile 类可以通过音频文件的路径进行初始化,并提供用于读取和处理文件内容的上下文管理器界面。

通过上下文管理器打开文件并读取文件内容,并将数据存储在 AudioFile 实例中,然后通过 record()将整个文件中的数据记录到 AudioData 实例中,可通过检查音频类型来确认:

在with块中调用record() 命令时,文件流会向前移动。这意味着若先录制四秒钟,再录制四秒钟,则第一个四秒后将返回第二个四秒钟的音频。

本程序从第 4.7 秒开始记录,从而使得词组 “it takes heat to bring out the odor” ,中的 “it t” 没有被记录下来,此时 API 只得到 “akes heat” 这个输入,而与之匹配的是 “Mesquite” 这个结果。
同样的,在获取录音结尾词组 “a cold dip restores health and zest” 时 API 仅仅捕获了 “a co” ,从而被错误匹配为 “Aiko” 。
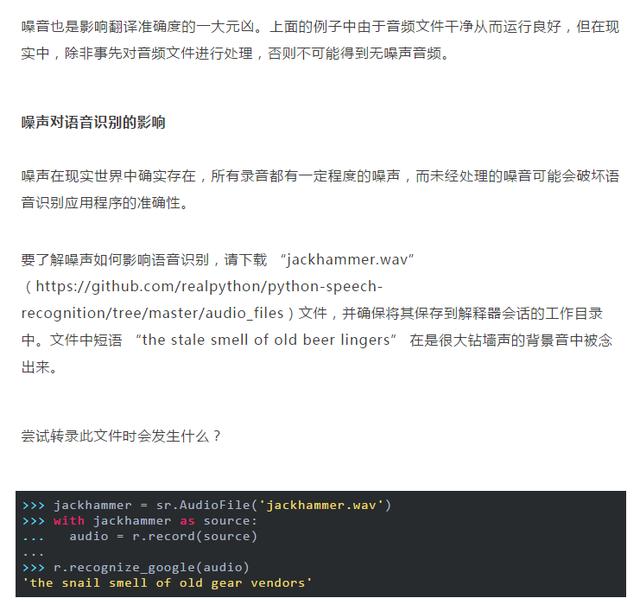
那么该如何处理这个问题呢?可以尝试调用 Recognizer 类的adjust_for_ambient_noise()命令。
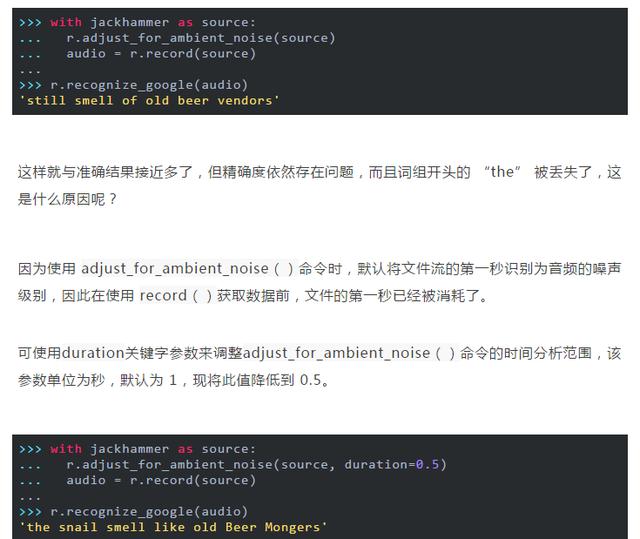
现在我们就得到了这句话的 “the”,但现在出现了一些新的问题——有时因为信号太吵,无法消除噪音的影响。
若经常遇到这些问题,则需要对音频进行一些预处理。可以通过音频编辑软件,或将滤镜应用于文件的 Python 包(例如SciPy)中来进行该预处理。处理嘈杂的文件时,可以通过查看实际的 API 响应来提高准确性。大多数 API 返回一个包含多个可能转录的 JSON 字符串,但若不强制要求给出完整响应时,recognition_google()方法始终仅返回最可能的转录字符。

▌麦克风的使用
若要使用 SpeechRecognizer 访问麦克风则必须安装 PyAudio 软件包,请关闭当前的解释器窗口,进行以下操作:
安装 PyAudio
安装 PyAudio 的过程会因操作系统而异。
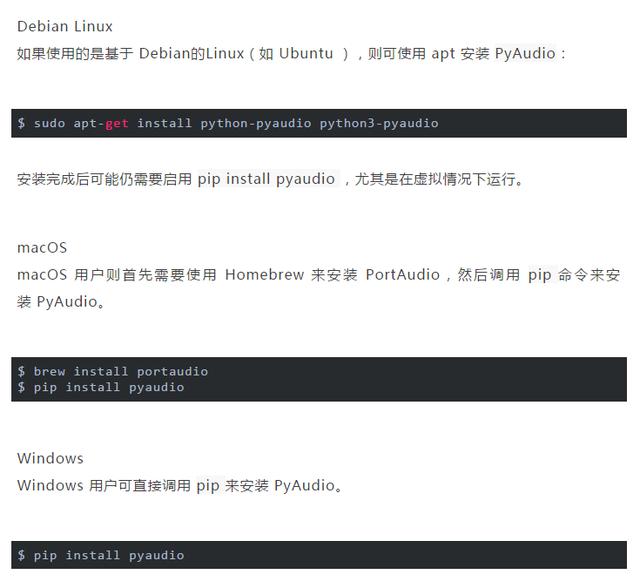
安装测试
安装了 PyAudio 后可从控制台进行安装测试。
$ python -m speech_recognition
请确保默认麦克风打开并取消静音,若安装正常则应该看到如下所示的内容:
A moment of silence, please...
Set minimum energy threshold to 600.4452854381937
Say something!
请对着麦克风讲话并观察 SpeechRecognition 如何转录你的讲话。
Microphone 类
请打开另一个解释器会话,并创建识一个别器类的例子。
>>> import speech_recognition as sr
>>> r = sr.Recognizer()
此时将使用默认系统麦克风,而不是使用音频文件作为信号源。读者可通过创建一个Microphone 类的实例来访问它。
>>> mic = sr.Microphone()


要处理环境噪声,可调用 Recognizer 类的 adjust_for_ambient_noise()函数,其操作与处理噪音音频文件时一样。由于麦克风输入声音的可预测性不如音频文件,因此任何时间听麦克风输入时都可以使用此过程进行处理。


进群:125240963 即可获取数十套PDF哦!

标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

下一篇:pythonday12
- python3基础之“术语表(2)” 2019-08-13
- python3 之 字符串编码小结(Unicode、utf-8、gbk、gb2312等 2019-08-13
- Python3安装impala 2019-08-13
- 小白如何入门 Python 爬虫? 2019-08-13
- python_字符串方法 2019-08-13
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
