问:
如dumeter所示,可以看到明显的中断在最后一次中断前,我使用ping 127.0.0.1 -t 命令进行了监测,ping是稳定的,但是访问无法到达,此时服务器,cpu均正常
请检查贵司宿主机!,网络不稳定,时断时续
问:
答:您好,
1、127.0.0.1 服务器网络我们检测是正常的。通过您提供的截图可能是内存到了瓶颈。2、我们远程登录提示此服务器登录用户数过多,无法进行登录。若需我们进一步排查,请您暂时勿进行其它调整服务器。非常感谢您长期对我司的支持!
问:1、这台机器几年来都是内存这么高,跑到14g家常便饭
2、这台机器的问题是从更换集群开始,历史工单如下https://www.west.cn/manager/questionnew/show.asp?qid=https://www.west.cn/manager/questionnew/show.asp?qid=https://www.west.cn/manager/questionnew/show.asp?qid=3、最后一次工单,贵司承诺“此情况已转交相关技术专家进行监测和分析,我司会持续观察此情况,非常感谢您长期对我司的支持.由此给您带来的不便之处,敬请原谅!谢谢!”4、在长期的排查过程中,我目前只能确定,问题和硬盘有关,每次故障的时候,硬盘都会报错,因此我把错误信息作为独立日志进行保存,如图所示,今天的两次故障仍然出现同样的硬盘问题,请查看由于这是云主机,我无法对物理硬盘产生影响,线路松动之类的都无法跟我产生关系。另外一个怀疑磁盘的原因,是这个问题出现的频率,刚开始很高,但是自从贵司处理了一次“云平台存储系统出现了异常,自动处理时会短暂影响IO性能”以后,问题就少见了很多。
问:为了避免贵司重复排查,我整理下这个问题产生的相关工单,如下
【问题表现】ping:通畅网络访问:无法访问,超时dumeter:外网流量中断内存:正常贵司性能视图cpu、硬盘:均正常并降低为0服务器操作:卡(注意,如果真的上面都正常,性能视图和服务器上cpu内存硬盘都正常,是不会卡的)
【问题排查过程】: 之前 未发现任何问题。内存占用一直都是14g ,且之前流量未目前的2倍,内存占用更高
统一更换宿主机集群
工单 更换宿主机集群后多次出现问题、首次提交工单,(已经自查过多次,只能怀疑到贵司宿主机上) ○ 贵司回复:“云平台存储系统出现了异常,自动处理时会短暂影响IO性能,我们目前已经解决相应的存储问题”
工单 再度提交工单 ○ 贵司回复:“日志没发现问题”,但是后续查了日志,相关时间是中断的!这个工单完全没有任何意义
工单 再度出现问题 ○ 贵司回复:“内存问题”,但是此次我发现,系统日志显示了viostor错误,指向磁盘(注意,性能视图和服务器监测显示磁盘没问题),为了考察两者关联性,我创建了监控日志,以确定是不是出现故障的时候,出现viostor错误。 ○ 贵司最终回复:“此情况已转交相关技术专家进行监测和分析,我司会持续观察此情况”
本工单,再度出现问题,确认系统日志伴随viostor错误,重点查看了磁盘的io,磁盘io显示正常。所以请排查下宿主机的磁盘。
答:您好,1.刚才网络有异常,我司已做调整,请继续观察。
2.如果愿意,可以更换一个集群my10g-2,数据量大,可能会中断1-2个小时。另外IP地址也会变。
问:本次工单进展如下:
1、与贵司电话客服沟通,谈到故障出现时,系统日志有viostor错误,没有故障的时候没有,贵司客服说这个错误很常见,为了确认这个情况,我在三台windows2008服务器上查看,分别为腾讯云,ucloud,以及一台物理服务器,均未发现同样的129错误。
2、请问网络异常是机房问题,还是服务器问题,贵司所指的网络调整是指,目前能否确认产生多次不定期访问故障的原因是这个网络问题?
3、如果第二点已经定位了问题,那可以不迁移,如果不能定位具体问题,那可否先在my10g-2集群镜像以后再迁移,实在不行,我新开一台my10g-2机房机器,贵司协助镜像后,将服务时长转移过去?谢谢。
问:补充说明,这个故障,一般情况下故障时间都是几分钟后,不做任何操作都会自动回复的
答:您好,
viostor错误与服务器卡没有必然关系,是机房内部网络问题引起,不会持续较长时间,您可以继续观察。您也可以在晚上空闲时间,关闭服务器,通过服务器管理-升级-更换机房线路,更换到my10g-2集群,期间会中断几个小时,非常感谢您长期对我司的支持!
问:1、您提到“viostor错误与服务器卡没有必然关系”,但是在这一次的工单,以及上一次的工单中,viostor错误与服务器卡 都一一对应出现,有卡顿的时候有错误,无卡顿无错误,这是否可以说明 viostor错误与服务器卡“有关系”?或者我换个说法,假设,我说的是假设,假设是这个viostor错误导致的,那么我需要监测哪些东西,提供什么样的证据来说明
2、您说的手工更换集群,就不会发生ip变化是么?
答:您好,我们以前遇到过该错误,服务器并不存在卡的情况。 更换集群ip会变化,非常感谢您长期对我司的支持!
问:1如果是之前遇到这个错误,服务器不会卡就能说明这个错误没有问题,那是不是这次错误出现卡顿可以说明卡顿和错误有关? 或者换个角度,为什么这台服务器的卡顿和这个错误对应了? 2 请问贵司是否已经找到了对应这几次卡顿的原因?确定是相关问题?如果没有,能否申请转主管处理
问:就在刚才, 18:40分,收到腾讯云报警,服务又中断了,如图
我查看服务器日志,再度出现相关错误,如图
这个情况可以说明1、贵司在 17:59:23的判断“是机房内部网络问题引起,已做调整” 是否未调整到位,或者,不是机房内部网络问题?
2、目前我观察到的,最大的相关因素,就是129错误报告和故障时间一一对应,如果贵司不考虑这一条线索,那么麻烦告诉我,我应该继续观察什么?我已经用了贵司服务15年了,不敢自称windows服务器专家,手上的服务器也搞了几十台了,我实在不知道该继续观察什么解决这个持续了2个多月,却一直解决不了的问题了,真的非常无助,每一次工单都要重新提交,都要重新说一遍,每一次都要重新排查什么内存,网站访问日志,真的非常无助疲倦,能否得到贵司专家的电话沟通服务?我可以付费
问:最后,我在微软找到了官方对于129错误引发故障的指南
https://learn.microsoft.com/zh-cn/archive/blogs/ntdebugging/undere-timeouts-and-event-129-errors根据微软的描述“I have never seen software cause an Event ID 129 error. If you are seeing Event ID 129 errors in your event logs, then you should start investigating the storage and fibre network.”,如果按照微软的说法,也指向了宿主机。
另外,vmware针对129错误日志也给出了他们的解决方案
https://kb.vmware.com/s/article/
希望有用,谢谢,拜托
问:补充,第四
根据我刚才所获得的微软及vmware的提示,我进行了以下操作尝试更新服务器的存储控制器驱动到最新版本,并重启
答:您好,这个原因很清晰,就是那天那个时刻集群后端有一台阵列卡损坏hang住,造成这个现象,坏的阵列卡当天我们已经更换,而且这个中断很短,服务可以自动恢复,且一般情况下用户感知不大,您可以再观察一下,谢谢。
问:感谢回复
1、您的回复是“这个中断很短,服务可以自动恢复,且一般情况下用户感知不大”
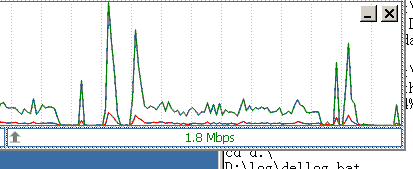
如图1所示,当日故障时段(16-17时),应用损失了75%%u7684流量。这一问题持续了一个多小时,虽然自动回复,但是用户感知极大
所以能否确认,当日的故障,以及之前所拥有同样表现得故障,都是来自阵列卡的损坏问题?
图1 流量损失70%
2、如果真的是由于阵列卡损坏问题,即,宿主机问题,那么从我们之前的工单沟通记录,如图2,可以明确看出,我已经将问题定位到了宿主机,但是由于贵司的工单机制,导致花费了大量时间进行了无效的排查和沟通
这不仅耽误了服务的恢复,也增加了贵司的工作量。
而且万一这个问题又复现了,那么,我是否又要重新重复上面工单、工单、工单、以及本工单的沟通过程?
因此,申请不要关闭这个工单,或者贵司提供一个解决方案,以便这个问题如果复现,可以提交到这个工单或者从这个工单延续,谢谢。
图2
答:您好,故障时间只有10来分钟,从17点开始,这10来分钟虚拟机应该是完全不可用的,您性能截图上,16点-17点之间其实还在正常提供服务,并未完全中断,所以这个时间段的故障应该与此无关,您可以再观察下,如果不放心,也可以给您更换一个集群,非常感谢您长期对我司的支持.由此给您带来的不便之处,敬请原谅!谢谢!
问:性能视图确实正常,cpu和硬盘都快没用上了,但是服务和远程都是中断的,这也是我怀疑贵司宿主机的原因,而且贵司的技术人员也去排查了服务器,没有结果 更换宿主机需要更换ip,而且如果你们没有定位出问题,更换宿主机也不能解决问题,所以我只能每天回复下这个工单,并希望是你们阵列卡坏
答:您好,问题已经定位并且解决了,此类故障几率相对比较低,自动程序、运维人员也都一直有监控。
问:我们假设问题已经解决,但是之前持续了两个多月,我也多次提了工单,问题表现形式也相同,但是当时却没有解决问题,所以请不要关闭这个工单,以便万一出现相同问题我直接在这个工单上提交
答:您好,工单系统会自动关闭,如有问题请新提交即可,我司会查看到之前提交过的工单。
问:从七月份开始,因为这个问题,我提交了4个工单,每一次都是重新查看,但是每一次都去做了一堆无用的排查以后还是没有解决问题,这就是我希望能保持这个工单开放的原因,如果你们没有其他保持工单方案那么可以不用回复这个工单,或者每次回复我提交一次疑问。
答:您好,下次如果遇到类似问题,要提醒 我们的话,可以注明:请参考工单。
,非常感谢您长期对我司的支持!
问:就在刚刚,再度出现访问中断,伴随129错误日志,外网无流量,性能监控显示内存cpu硬盘都正常,请排查宿主机硬盘及驱动
答:您好,
该集群近期排查到部分后端存储的风扇设置功率过高,有较大几率形成共振导致硬盘损坏。因此我司决定逐台停机检修。检修过程中对部分云主机可能 造成短时间的卡顿现象。如果对稳定性要求较高,可以联系我们迁移至其他集群。IP可以保持 不变,迁移是自动的,只是迁移过程中有短时间的中断。,非常感谢您长期对我司的支持.由此给您带来的不便之处,敬请原谅!谢谢!
